Java Reactive Programming Walkthrough -- Project Reactor
Reactive programming offers a paradigm shift for handling data flows and concurrency. This tutorial explores its core concepts, benefits, and implementation using Project Reactor and Spring Boot.
Sources:
Understand the Default Blocking Model
Java's default blocking model processes requests sequentially, where each operation blocks the thread until completion. While simple, it has significant drawbacks for modern applications, especially in microservices architectures:
- Inefficient for High Concurrency:Blocking threads during I/O operations (e.g., waiting for service or database responses) leads to resource underutilisation.
- Not Optimized for Microservices: Microservices often involve multiple dependent calls between services. A blocking model introduces cumulative delays, increasing latency and degrading performance for latency-sensitive applications.
- Increased Cloud Costs: In cloud-hosted environments, idle threads waiting on I/O waste resources, leading to higher infrastructure costs under heavy workloads. Modern demands for scalability, responsiveness, and cost-efficiency highlight the need for non-blocking, asynchronous paradigms better suited for microservices and cloud-native applications.
What is Reactive Programming?
Reactive programming is a declarative programming paradigm focused on data streams and change propagation. Instead of specifying how to perform tasks, developers define what should happen when data becomes available.
Key Characteristics:
- Asynchronous Execution: Tasks like I/O operations run in the background, freeing threads to handle other requests
- Non-Blocking: Threads avoid waiting for slow operations to complete
- Efficient Resource Use: Fewer threads manage more requests, reducing overhead.
Classical uses of reactive programming include Graphical User Interfaces (web or browser apps) where the system reacts to user events, and real-time data streams (e.g., sensor data, stock markets, real-time messaging) where data is communicated continuously between systems.
Real-world analogy: Blocking vs Reactive Programming
Imagine you are managing a to-do list for your online shop, which includes the following tasks:
- Pick up clothes (takes 10 minutes)
- Prepare packaging boxes (10 minutes)
- Print delivery labels (10 minutes)
- Finish packaging (10 minutes)
- Drop off to the carrier (5 minutes)
A sequential approach takes 45 minutes. Reactive programming delegates available tasks to multiple workers, completing them in parallel and reducing total time. For example:
- Person 1 picks up clothes
- Person 2 prepares the packaging boxes
- Person 3 prints labels
- When all three tasks are done, the packages are finished are dropped to carrier.
The total time in this case is 25 minutes.
Async Alternatives: Futures vs Reactor
Before Project Reactor, Java offered CompletableFutures for asynchronous workflows:
// CompletableFutures implementation
public User getUser(String userId) {
// Fetch user data asynchronously
CompletableFuture<User> userAsync = CompletableFuture.supplyAsync(() -> userService.getUser(userId));
// Fetch user preferences asynchronously
CompletableFuture<Preferences> prefsAsync = CompletableFuture.supplyAsync(() -> userPreferencesService.getPreferences(userId));
// Wait for both asynchronous operations to complete
CompletableFuture<Void> bothFutures = CompletableFutures.allOf(userAsync, prefsAsync);
bothFutures.join();
// Retrieve the results of the completed asynchronous operations. Blocks main thread
User user = userAsync.join();
Preferences prefs = prefsAsync.join();
user.setUserPreferences(prefs);
return user;
}
vs
// Project Reactor
public Mono<User> getUser(String userId) {
return userService.getUser(userId) // Fetch the User object reactively
.zipWith(userPreferencesService.getPreferences(userId) // Combine the result of fetching the User with the User Preferences
.map(tuple -> { // when both calls are done, perform transformation of result
User user = tuple.getT1();
user.setPreferences(tuple.getT2());
return user;
}); // return a single asynchronous computation that emit a User once completed.
// Doesn't block the main thread at all
}
Chaining multiple CompletableFuture calls can be functional but often becomes verbose and prone to errors. In contrast, Project Reactor provides a framework for making asynchronous calls that features a simpler syntax. It includes several reusable and familiar functions that can be combined in powerful ways. Additionally, it offers increased control over data streams and maintains a non-blocking nature.
Reactive Programming in Java
Core concepts
Traditional patterns handle data flow in two ways:
- Iterator (Pull): Consumers controls data flow, explicitly requesting each item sequentially (e.g., Iterator.next())
- Observe (Push): Producer drives flow, publishing data to consumers (e.g., event listeners)
Reactor combines both approaches through a Publisher-Subscriber model with back-pressure. The core abstractions are:
- Publisher: Emits data sequences when available (Flux / Mono)
- Subscriber: Consumes data with back-pressure control (e.g., request 10 items at a time)
- Subscription: Controls flow rate between Publisher and Subscriber
Conveyor Belt Analogy
To better understand the Reactive abstractions, it is useful to think of a smart conveyor belt line:
- Publisher = Places items (data) on the belt.
- Subscriber = Worker processing items at their pace
- Subscription = Conveyor belt with adjustable speed
- Back-pressure = Worker's "slow down!" signal
// Production line processing 100 items
Flux.range(1, 100).delayElements(Duration.ofMillis(100L) // Start production
.map(item -> processItem(item)) // Transform items
.bufferTimeout(10, Duration.ofSeconds(1)) // Batch processing
.flatMap(batch -> {
return Flux.fromIterable(batch)
.parallel() // Multiple workers
.runOn(Schedulers.boundedElastic()) // Worker threads
.doOnNext(item -> workOnItem(item));
})
.subscribe(
item -> recordCompletion(item), // Success handling
error -> handleError(error), // Error handling
() -> shutdownLine() // Completion handling
);
Publishers
The Publisher<T> interface is the foundation of reactive streams. It declares a single method
void subscribe(Subscriber<? super T> subscriber);
This binds a Publisher to a Subscriber, initiating the data flow.
Project Reactor provides two Publisher implementations:
Mono<T>: Emits 0 or 1 item, followed byonCompleteoronErrorevents
Mono<String> singleItem = Mono.just("Hello");
Mono<String> empty = Mono.empty();
Mono<String> error = Mono.error(new RuntimeException());
Flux<T>: Emits 0 to N items followed byonComplete/onError
Flux<?> unresponsive = Flux.never();
Flux<String> letters = Flux.just("A", "B");
Flux<Integer> numbers = Flux.range(1, 5);
Flux<String> fromCollection = Flux.fromIterable(List.of("A", "B"));
Flux<?> fromGenerator = Flux.generate(() -> 0, (state, sink) -> { ... })
Flux<Long> interval = Flux.interval(Duration.ofSeconds(1));
Types of emitted events:
onNext: Delivers an item to the Subscriber.onComplete: Signals successful stream completion.onError: Signals failure (by default, theSubscriberstops listening toPublisher, but this behaviour can be overwritten)
Subscribers
The Subscriber<T> interface defines methods to react to events:
void onSubscribe(Subscription s);
void onNext(T item);
void onError(Throwable t);
void onComplete();
The Subscription interface controls back-pressure and cancellation:
void request(long n); // Ask for `n` items
void cancel(); // Stop receiving data
BaseSubscriber<T> is a helper class simplifying custom Subscriber implementations. Override lifecycle hooks:
hookOnSubscribe(Subscription): Called on subscription (for example, to initialize back-pressure)hookOnNext(T): Process an itemhookOnError(Throwable): Handle errorshookOnComplete(): Clean up after completion
Example: Batched Processing
public class BatchSubscriber<T> extends BaseSubscriber<T> {
private final int batchSize;
private List<T> buffer = new ArrayList<>();
public BatchSubscriber(int batchSize) {
this.batchSize = batchSize;
}
@Override
protected void hookOnSubscribe(Subscription subscription) {
// Request first batch
request(batchSize);
}
@Override
protected void hookOnNext(T value) {
buffer.add(value);
if (buffer.size() >= batchSize) {
processBatch(buffer);
buffer.clear();
request(batchSize); // Request next batch
}
}
private void processBatch(List<T> batch) {
// Custom logic (e.g., save to database)
}
}
// Usage
Flux.range(1, 100).subscribeWith(new BatchSubscriber<>(10));
Subscription control:
request(n): Adjusts back-pressure (e.g., request 10 items at a time)cancel(): Stops the stream (e.g., user aborts operation)dispose()(Reactor specific): Releases resources when the steam ends.
Operators
Reactor's operators mirror Java Streams but work asynchronously:
// Java Stream (synchronous)
List<Integer> evenNumbers = IntStream.range(1, 10)
.filter(n -> n % 2 == 0)
.map(n -> n * n)
.forEach(System.out::println);
// Reactor (asynchronous)
Flux.range(1, 10)
.filter(n -> n % 2 == 0)
.map(n -> n * n)
.subscribe(System.out::println);
Notable operators that facilitate the manipulation and transformation of reactive streams:
subscribe: Initiates the subscription to aMonoorFlux, triggering the flow of data. It can accept various parameters, such as consumers foronNext,onError, andonCompletesignals, as well as anonSubscribeconsumer. This operator is essential for starting the reactive stream processing.map: Transforms each element of the sequence by applying a synchronous function, similar toStream.mapflatMap: Transforms each element into a Publisher and flattens these into a single sequence, akin toStream.flatMapfilter: Selects elements that match a given predicate, equivalent toStream.filterreduce: Combines elements sequentially to produce a single result, comparable toStream.reducecollect: Accumulates elements into a collection or other mutable container, similar toStream.collectbuffer: Collects emitted items into a collection (e.g.,List) and emits these collections asFlux<List<T>>. This is useful for batching items before processing. For example,buffer(5)collects items into lists of 5distinct: Suppresses duplicate elements, analogous toStream.distinctsort: Orders elements according to a comparator, comparable toStream.sortedlimit: Restricts the sequence to a specified number of elements, similar toStream.limitskip: Ignores a specified number of elements in the sequence, akin toStream.skipany,all: Evaluate whether elements match a given predicate, similar toStream.anyMatch,Stream.allMatch.log: Logs various events in the reactive stream, includingonSubscribe,onNext,onError, andonComplete. This is particularly useful for debugging and monitoring the flow of data. The log operator integrates with common logging frameworks likeLog4JandSLF4J
How to Decipher Reactor documentation
The best way to learn about and understand how operators work in Project Reactor is by reading the official documentation. The page titled "Which Operator Do I Need?" will guide you through all the operators and explain their use cases.
Another common challenge is understanding the "marble diagrams" or graphical representations included in the operator's Javadoc. You'll encounter these diagrams frequently while reading the documentation, so it’s important to review the explanation seen below.
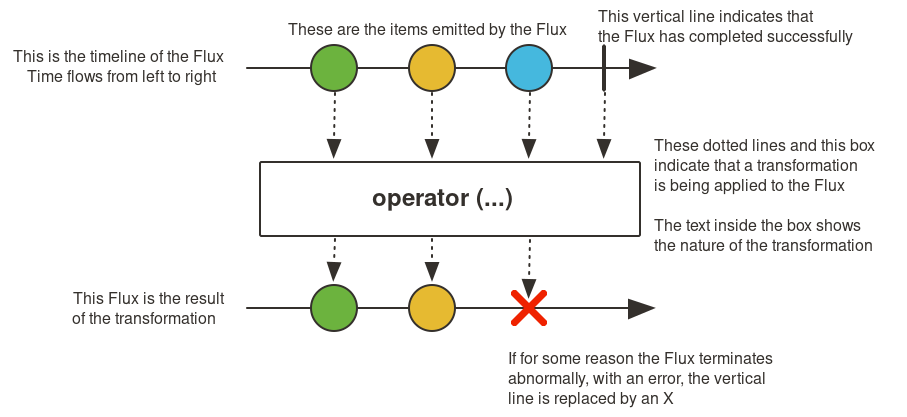
Common Patterns and Pitfalls
Error Handling
Use operators to mange errors gracefully:
onErrorResume: Fallback to an alternative streamonErrorReturn: Return a default valuedoOnError: Log error without affecting the stream
Timeouts
Subscription
Always subscribe to start processing. Without subscribe, the conveyor belt is not started, and the data does not flow.
Blocking calls
Avoid mixing blocking code (e.g., database calls, Thread.sleep) with reactive code. Use dedicated schedulers for blocking operations.
Exercises
Congratulations on completing this walkthrough! Now it's time to put your knowledge to the test. Please go ahead and solve these exercises designed to help you strengthen your reactive Java skills https://github.com/pahautelman/reactive-java-workshop.
Reactive Spring Boot
Spring WebFlux integrates Project Reactor into Spring Boot, enabling non-blocking REST APIs. Controllers return Mono and Flux, repositories use reactive drivers (e.g., R2DBC for databases)
The benefits include
- scalability: Handle more requests with fewer threads, WebFlux can handle 10k+ requests with minimal threads
- responsiveness: Maintain performance under high load.
For a reference skeleton on how to set up a reactive Spring Boot project, please visit https://github.com/pahautelman/reactive-spring-skeleton.